
Data-Pipeline
This project automates the process of ingesting CSV files, creating a PostgreSQL database, analyzing data structure using llm's, and generating SQL transformations for data cleaning and normalization.
Learn more
Visualize voter-data using Tableau.
Learn more
Explore and clean data using R scripts, with visualizations created by ggplot.
Learn more
Manage project workflows by incorporating version control with Git and GitHub.
Learn moreGallery of work.
This project automates the process of ingesting CSV files, creating a PostgreSQL database, analyzing data structure using llm's, and generating SQL transformations for data cleaning and normalization.
Learn more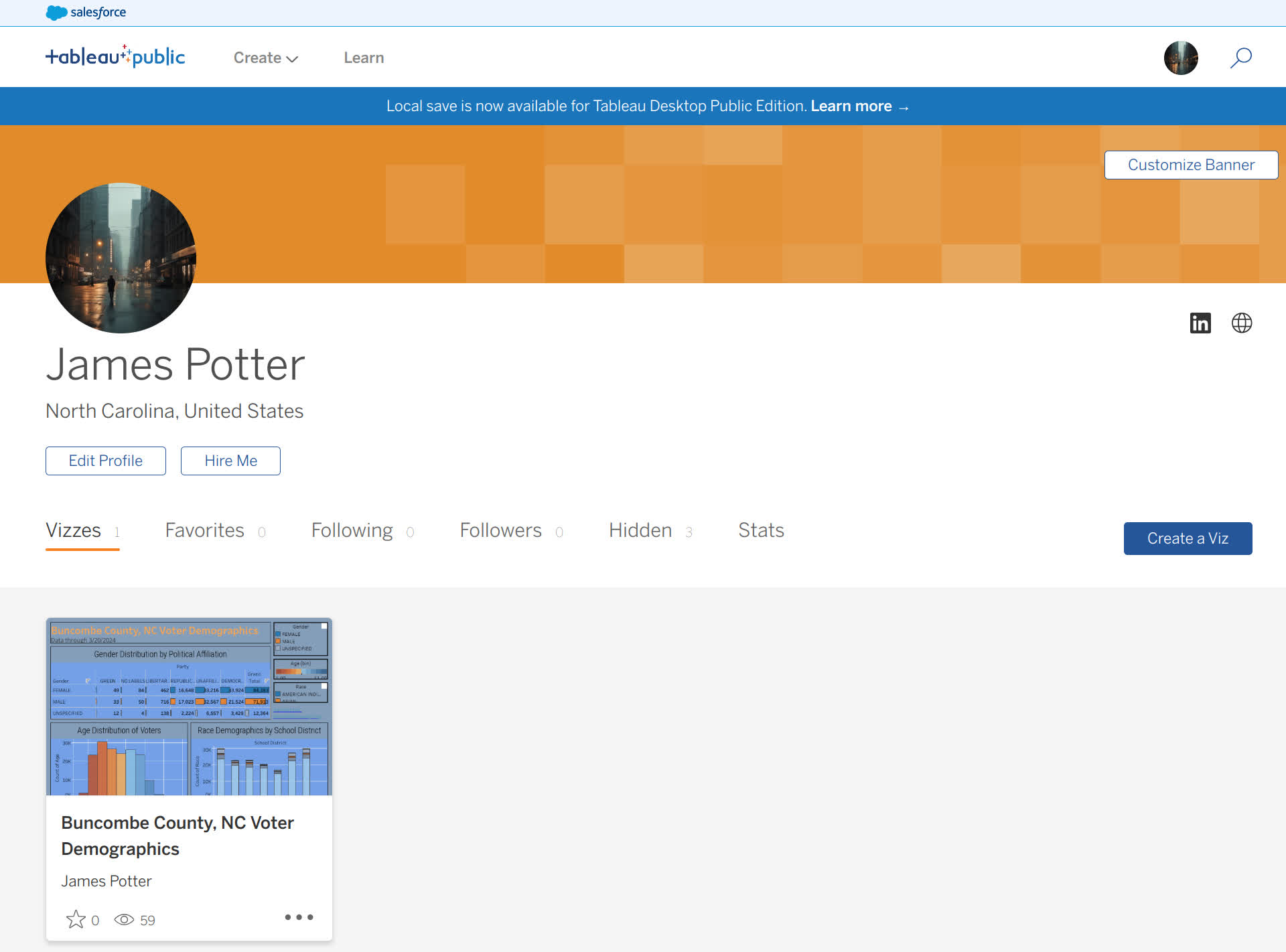
A broad analysis of voter demographics in Buncombe County, North Carolina. Utilizing R and its powerful libraries, we dive deep into the data to uncover the intricate patterns of voting behavior and demographic intersections within this region. Our project aims to provide stakeholders, policymakers, and the general public with actionable insights into the demographics of voters, focusing on their party affiliations, racial compositions, gender distributions, age groups, and geographic distributions across zip codes and school districts.
Learn more
Explore the repo.
Learn more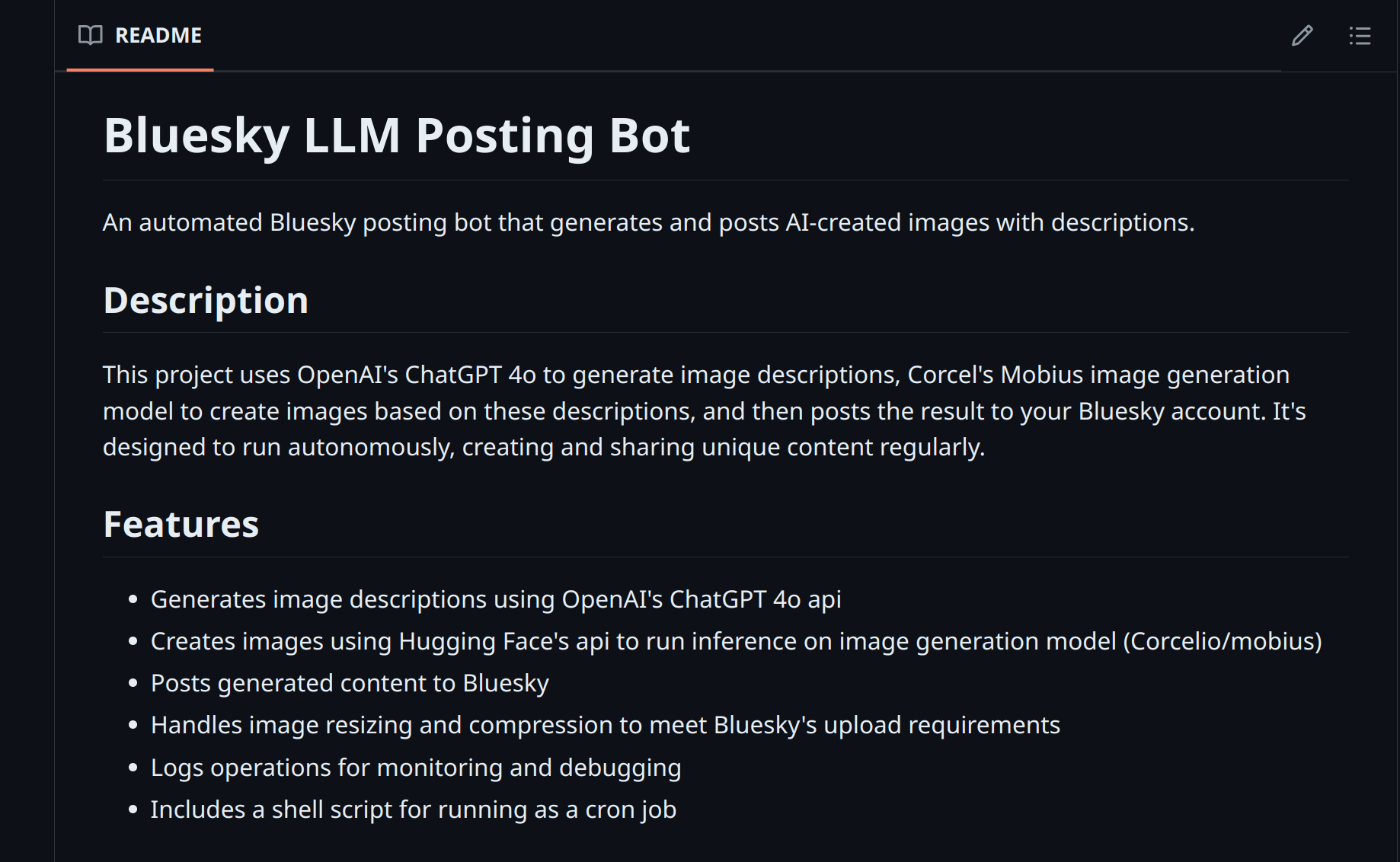
An automated Bluesky posting bot that generates and posts GenAI-created images with descriptions.
Learn more
This project demonstrates the effectiveness of machine learning in automating stellar classification, providing a robust and scalable solution for differentiating between giant and dwarf stars. The integration of a PostgreSQL database enhances data accessibility and management, laying the foundation for future research and analysis in astrophysical studies. Future work may include refining the model with additional features, exploring other classification algorithms, and expanding the dataset to include more diverse stellar types.
Learn more